
本插件用于聊天用机器人,而非功能性机器人。为 Koishi.js 调用 OpenAI 的语言模型。暂无本地化支持。

- 支持使用
pinecone向量数据库(可以免费注册)存储长期记忆,大大提升了记忆范围。(未启用时仅在本地存储短期记忆)(注意!OpenAI的Embeddings长度为1536,所以你的向量数据库创建时的索引长度(Index Dimensions)需要是1536!否则Embeddings保存不全)。相似度算法(Metric)请使用默认的Cosine。 - 基于
pinecone的关联检索功能,可以更准确地从听过的话中获取信息。 - 提供
WolframAlpha推理模块来尽可能计算参考答案(可以免费申请AppID),可以更好地回答如“3^99等于几”、“sin(x^2)的积分是什么”、“一加仑等于多少毫升”这类问题。需要能访问Google(非API,可能被限制,需要代理)。如果不行,则需要提供Bing翻译API(免费注册)。如果两者都不可用,推理模块就只对英语有反应了( ╯□╰ )2333 - 利用
google搜索(非API,可能被限制,需要代理)实现检索模块,对回答中的常识性无知进行规避(可以更好地回答时效性强的问题,比如新闻)。如果不行,可以用Bing搜索API(免费注册)。两者都不可用时使用Baidu搜索。注意!个大搜索引擎的搜索结果的质量参差不齐,有时候会搜到广告 - 简化了模型配置项,加载插件时自动选择一类模型中的
最新版(如选择turbo则自动应用gpt-3.5-turbo)。 - 重构了
记忆的储存方式,使用Embeddings和文本形式分别储存长期记忆和短期记忆,提升了记忆检索的效率。 - 移除了对
openai、pinecone等库的依赖,全面换用ctx.http.post/get等koishi的API,以便解决代理问题。 - 改善了Logger的输出,方便调试。
-
“为什么挂了代理一直报错?”
-
“为什么某个功能好像没用?”
- 答:因为你没有正确配置相关的功能。详见配置参考。
-
为什么长时间没更新?
- 开发者
太蔡了,而且最近忙着搞毕设,没什么时间写代码……///(つ﹏⊂)///…… - 如果你有想实现的功能,欢迎PR~
- 开发者
- ta 被
直接呼叫了(@名字,或回复/引用其消息,或者聊天时直呼其名) - ta 正在和你
私聊 - 你取得了 ta 的
随机注意
- 插件刚刚开始运行时,机器人的记忆有大量空白,因此表现具有
随机性与可塑性。尤其是连接向量数据库后,最开始会返回看似毫不相关的联想结果(不过基本上都被各种逻辑过滤掉了,如果你关注控制台就可以看到联想有多么的奇葩)。经过一段时间、一定量的对话以后,随着记忆逐渐成型,机器人的说话方式也逐渐定型(联想也越来越准)。因此建议机器人刚刚建立的时候走心地和ta说话,因为你最初和ta说的话决定了ta是个什么样的机器人。 - 机器人的
人设和示例对话大有讲究,可以多试试。 - 如果回复巨慢无比,是因为你的
网络环境不怎么好,或者是OpenAI的服务器高负载,无力了……
| 参数 | 作用 | 取值范围 | 建议值 |
|---|---|---|---|
| apiKey | 调用OpenAI API | - | 填写你的OpenAI API Key |
| apiAddress | 调用OpenAI API的地址 | - | 填写你的OpenAI API调用地址 |
| chatModel | 选择语言模型
|
turbodavincibabbagecurieada
|
turbo是效果最好的 |
| keywordModel | 选择关键词模型
|
curiebabbageada
|
curie是效果最好的 |
| codeModel | 选择代码模型
|
davincicushman
|
davinci是效果最好的 |
| 参数 | 作用 | 取值范围 | 建议值 |
|---|---|---|---|
| botName | 机器人的名字
|
- | 不要太长 |
| isNickname | 是否允许全局设置中的昵称触发AI回复 |
truefalse
|
true |
| botIdentity | 机器人人设的重要组成部分 |
- | 提到名字请用<NAME>代替。建议不超过200字 |
| sampleDialog | 机器人初始说话习惯的主要组成部分 |
- | 维持自洽,且不要太多/太长,否则容易消耗大量token。建议5条以内,每条20字左右 |
| 参数 | 作用 | 取值范围 | 建议值 |
|---|---|---|---|
| cacheSize | 机器人短期记忆的容量/条
|
2~32 |
根据回答长度酌情调整,固定占用token数为条数x每条的token数
|
| cacheSaveInterval | 机器人短期记忆的保存间隔
|
>=1 |
单位条,建议每隔4~8条保存一次 |
| cacheSaveDir | 机器人短期记忆的保存路径
|
- | 是koishi根目录开始的相对目录。建议保留默认的'cache'
|
| pineconeKey |
pinecone数据库的API密钥,填写后启动长期记忆、联想搜索等功能 |
- | 填写你自己的API密钥 |
| pineconeReg |
pinecone数据库的地区,形如us-east1-gcp
|
- | 填写你自己的数据库实例的地区 |
| pineconeIndex |
pinecone数据库的索引名 |
- | 填写你自己的数据库实例的索引名 |
| pineconeNamespace |
pinecone数据库的命名空间
|
- | 填写你自己的命名空间,或保留默认的'koishi'
|
| pineconeTopK |
pinecone数据库的最大返回条数
|
1~3 |
建议2,提高则快速消耗token数且会让AI分心
|
| 参数 | 作用 | 取值范围 | 建议值 |
|---|---|---|---|
| wolframAppId |
wolfram的appid,用于计算 |
- | 填写你自己的appid |
| azureTranslateKey |
Bing翻译API的密钥,用于在Google不可用时为wolfram提供翻译 |
- | 填写你自己的API密钥 |
| azureTranslateRegion |
Bing翻译API的地区,形如eastasia
|
- | 填写你自己的API地区,默认是global
|
| searchOnWeb |
搜索模块的开关
|
truefalse
|
默认开启,视网络情况和具体用例填写 |
| searchTopK |
搜索模块的最大条数,用于提升知识广度 |
1~3 |
建议1,提高则快速消耗调用次数且会让AI分心
|
| azureSearchKey |
Bing搜索API的密钥,用于在Google不可用时为搜索模块提供搜索 |
- | 填写你自己的API密钥 |
| azureSearchRegion |
Bing搜索API的地区,形如eastasia
|
- | 填写你自己的API地区,默认是global
|
| 参数 | 作用 | 取值范围 | 建议值 |
|---|---|---|---|
| isReplyWithAt | 是否在回复消息时@发送者,仅用于群聊 |
truefalse
|
false |
| msgCooldown | 消息冷却时间/秒,在此期间机器人不会响应消息 |
1~3600 |
根据网络情况酌情调整,使得API总在下次调用之前返回 |
| nTokens | 机器人回复的最大长度
|
16~512 |
必须是16的整数倍,建议128~256之间。提高则快速消耗token数 |
| temperature | 回复温度,越小越固定,越大越随机
|
0~1 |
建议0.7~1之间 |
| presencePenalty | 越大越会避免出现过的token,和出现次数无关
|
-2~2 |
建议0左右 |
| frequencyPenalty | 越大越会避免频繁出现的token,出现次数越多越受该参数影响 |
-2~2 |
建议0左右 |
| randomReplyFrequency |
随机对某句话产生兴趣并回复的概率 |
0~1 |
不要太高,否则万一被刷屏容易消耗大量token。建议0.1~0.3之间 |
| 参数 | 作用 | 取值范围 | 建议值 |
|---|---|---|---|
| isLog | 向控制台输出日志信息 |
truefalse
|
建议true,有助于了解运行状态 |
| isDebug | 向控制台输出调试信息 |
truefalse
|
建议false,否则会大大增加日志长度 |
| ChatGPT | @tomlbz/koishi-plugin-openai |
|---|---|
 |
 
|
 |
 
|
 |
 
|
从下面这张图可以看到几个功能:
- 大部分时候
长期记忆都发挥着主要作用,机器人不需要也不会一直上网搜索。 - 当
OpenAI的API报错的时候,机器人的当条回复中断了,但这并不影响它继续回复下一条消息。 - 机器人的联想
乱七八糟(仔细一看发现跟话题八竿子打不着),但是话题并不很受到乱七八糟的联想的影响(费了老鼻子劲了!)。 - 你可以用它给他自己debug(
不)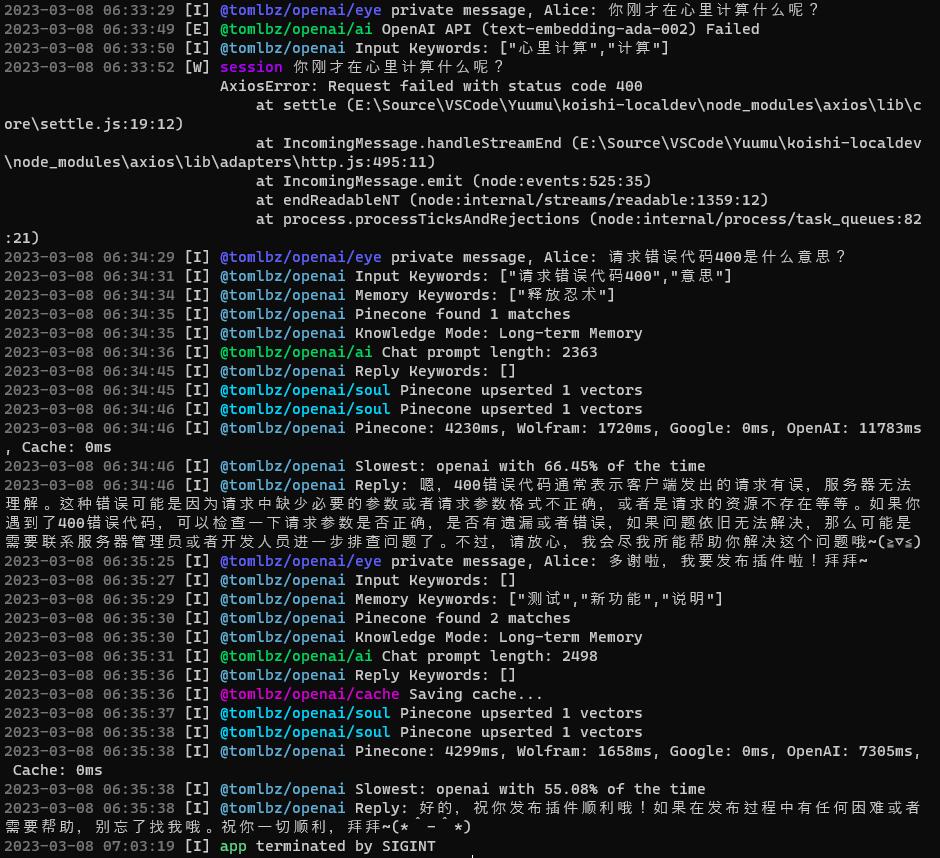

# in koishi-app dir
# build
npm run build openai
# pub
npm run pub openai