



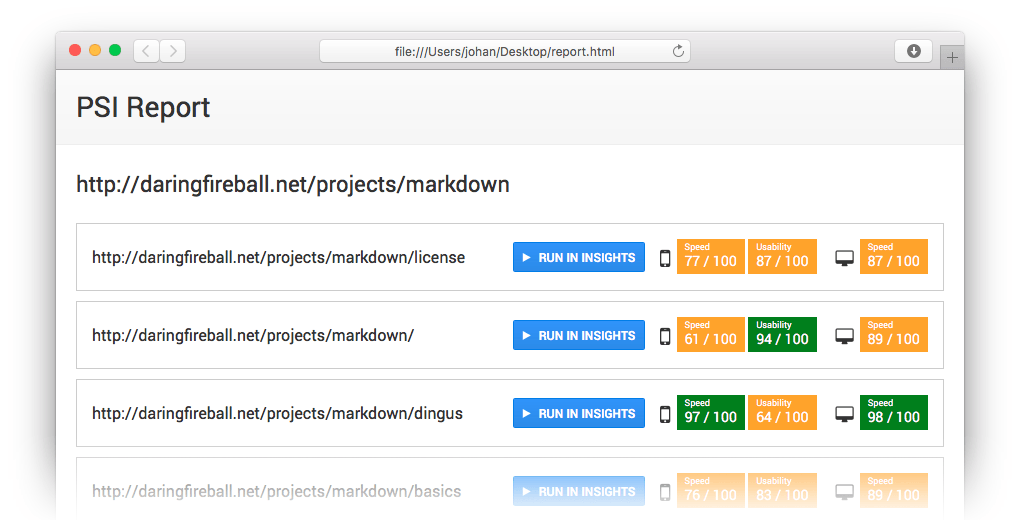
psi-report
Crawls a website or get URLs from a sitemap.xml or a file, gets PageSpeed Insights data for each page, and exports an HTML report.
Installation
Install with npm:
$ npm install psi-report --global# --global isn't required if you plan to use the node module CLI usage
$ psi-report [options] <url> <dest_path>Options:
-V, --version output the version number --urls-from-sitemap [name] Get the list of URLs from sitemap.xml -h, --help output usage informationExample:
$ psi-report daringfireball.net/projects/markdown /Users/johan/Desktop/report.htmlProgrammatic usage
// Basic usage var PSIReport = ;var psi_report = baseurl: 'http://domain.org' onComplete;reporterstart; { console; console; // An array of pages with their PSI results console; // The HTML report (as a string)} // The "fetch_url" and "fetch_psi" events allow to monitor the crawling process psi_report;{ console;} psi_report;{ console;}Crawler behavior
The base URL is used as a root when crawling the pages.
For instance, using the URL https://daringfireball.net/ will crawl the entire website.
However, https://daringfireball.net/projects/markdown/ will crawl only:
https://daringfireball.net/projects/markdown/https://daringfireball.net/projects/markdown/basicshttps://daringfireball.net/projects/markdown/syntaxhttps://daringfireball.net/projects/markdown/license- And so on
This may be useful to crawl only one part of a website: everything starting with /en, for instance.
URLs from a sitemap.xml or a file
Instead of crawling the website, you can set the URL list with a sitemap.xml or a file.
--urls-from-sitemap https://example.com/sitemap.xml--urls-from-file /path/to/urls.txt
Only the URLs inside this file will be processed.
Changelog
This project uses semver.
| Version | Date | Notes |
|---|---|---|
2.2.1 |
2018-01-19 | Fix missing source files on NPM (@blaryjp) |
2.2.0 |
2017-11-27 | Prepend baseurl if not present, for each urls in file (@blaryjp) |
2.1.0 |
2017-11-19 | Add --urls-from-sitemap and --urls-from-file (@blaryjp) |
2.0.0 |
2016-04-02 | Deep module rewrite (New module API, updated CLI usage) |
1.0.1 |
2016-01-15 | Fix call on obsolete package |
1.0.0 |
2015-12-01 | Initial version |
License
This project is released under the MIT License.